Département de pharmacie
Faculté de médecine
Université de Constantine 3
Faculté de médecine
Université de Constantine 3


| Département de Pharmacie | |
| Enseignants / Tuteurs | |
| Organisation Pédagogique | |
| - Programme officiel | |
| - Plan de cours | |
| - Emploi du temps | |
| - Notes de cours | |
| 1. Situation problème | |
| 2. Statistiques descriptives | |
| 3. Théorèmes fondamentaux de probabilité | |
| |
| |
| |
| |
| 8. Estimation | |
| 9. Théorie générale des tests d'hypothèse, intervalles de pari | |
| 10. Comparaisons de moyennes | |
| 11. Comparaison de proportions | |
| Ressources | |
| Projets | |
| Bibliographie |
| ESPACE PRIVÉ |
| Accées Plateforme |
| Résultats des évaluations |
 |  |
Statistiques descriptives
V. Mesures échantillonnales
De manière générale, les données dont on dispose
peuvent se présenter selon une des formes suivantes :
L’âge de 15 étudiants :
- Des données en série : on note dans ce cas, xx , x2 , ..,xn les n observations de l’échantillon.
L’âge de 15 étudiants :
| 18 17 21 17 19 19 20 17 19 25 27 16 18 27 18 |
Des données sont regroupées en valeurs (dans un
tableau de fréquence : on note v1
, v2 , ..,vn, les k différentes valeurs observées et f1, f2, .., fk,
leurs effectifs ou fréquences absolues
Exemple 20
Des données regroupées en classe (tableau de fréquence)
Exemple 20
| Age des étudiants | Effectif |
| 16 17 18 19 20 21 25 27 | 1 3 3 3 1 1 1 2 |
| Total | 15 |
Des données regroupées en classe (tableau de fréquence)
| Age des étudiants | Centre de la classe | Effectifs |
| [16, 20[ | 18 | 10 |
| [20, 24[ | 22 | 2 |
| [24,28[ | 26 | 3 |
| Total | 15 |
1. Mesure de tendance centrale
Les trois principales mesures de tendance centrale sont : la moyenne, la médiane et le mode
1.1. La moyenne
Il s'agit du paramètre le plus connu et du plus
utilisé. C'est le point d'équilibre des observations.
Selon le type de données, la moyenne d’un échantillon se calcul de la manière suivante :
| Échantillon | |
| Données bruts | 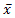 = (1 / n ) . = (1 / n ) . 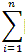 xi xi |
| Données groupées en valeurs | = (1 / n ) . vi . fi |
| Données groupées en classe | = (1 / n ) . 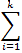 mi . fi mi . fiavec k = nombre de classes. |
Remarque
La moyenne n’est
pas une bonne mesure puisqu’elle est influencée par les valeurs extrêmes.
) et la moyenne dans la population (le paramètre
µ). Le calcul de µ se calcul de façon équivalente à la moyenne
échantillonnale :| Population | |
| Données bruts | µ = (1 / n ) . xi |
| Données groupées en valeurs | µ = (1 / n ) . vi . fi |
| Données groupées en classe | µ = (1 / n ) . mi . fi avec k = nombre de classes. |
1.2. La médiane
À la différence, de la moyenne n'est pas issue d'un calcul. Il s'agit de la valeur qui sépare les observations en deux parties égales telles qu'il y ait autant d'observation au-dessus qu'au-dessous.
La médiane sera avantageusement utilisée lorsque le nombre de valeurs est important.
Me = 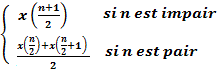
Lorsque les données sont regroupées en classe, on a recours à une approximation par une méthode graphique ou par une approche analytique.
- Méthode graphique : où on utilise le graphique des
fréquences cumulées. On repère la valeur qui correspond à 50% des obervations
cumulées.
- Méthode analytique : On utilise la formule suivante :
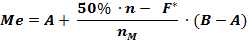
[A,B] : la classe qui contient la médiane
NM : l’effectif de la classe [A,B]
F* : la somme des effectifs des classes précédant la classe [A,B]
n : le nombre total d’observation
La médiane est aussi une mesure de position ; c’est le 2ème quartile.
Elle est une mesure robuste puisqu’elle n’est pas influencée par les valeurs extrêmes.
1.3. Le mode
1.4. Choix de la mesure de tendance
Le mode de l’échantillon noté Mo, est
la valeur la plus fréquente constatée dans les observations.
Il faut noter que le mode n’est pas toujours unique. C’est également une mesure robuste puisqu’il n’est pas influencé par les valeurs extrêmes.
Il faut noter que le mode n’est pas toujours unique. C’est également une mesure robuste puisqu’il n’est pas influencé par les valeurs extrêmes.
1.4. Choix de la mesure de tendance
En pratique, il est toujours conseillé de
commencer par faire une représentation graphique des données et ce n’est
qu’après qu’on choisi la mesure de tendance centrale à privilégier
| La mesure de tendance | Condition d'utilisation |
| La moyenne | Distribution relativement symétrique et unimodale |
| La médiane | Distribution avec forte asymétrie (positive ou négative) et unimodale |
| Le mode | Distritribution multimodale Variable qualitative nominale |
 |  |  |